DOM 객체에 대해 - 2
2주 간의 공백이 있었다. 건강이 최우선이다.
개요
이전에 DOM 객체에서 다룬 포스팅에서는 DOM 객체가 HTML 문서의 외부에서 HTML 을 다룰 때 사용할 수 있는 interface 라는 것과 Javascript 를 통해 DOM 에 접근해 문서의 요소에 접근할 수 있다는 것을 알았다.
추가할 내용, interface 는 쉽게 생각하면
“document.getElementById(id)”, “document.getElementsByTagName(name)”, “querySelector()” 이와 같은 것들이라고 할 수 있다.
JS 에서 이런 interface 를 통해서, Object 에 접근하는 것!
DOM의 구조
이번에는 그 구조에 대해서 조금 더 다루어 볼 것이다.
먼저, 이전 포스팅에서 언급했던 것 처럼 HTML 문서를 브라우저에서 DOM 으로 구조화해준다.
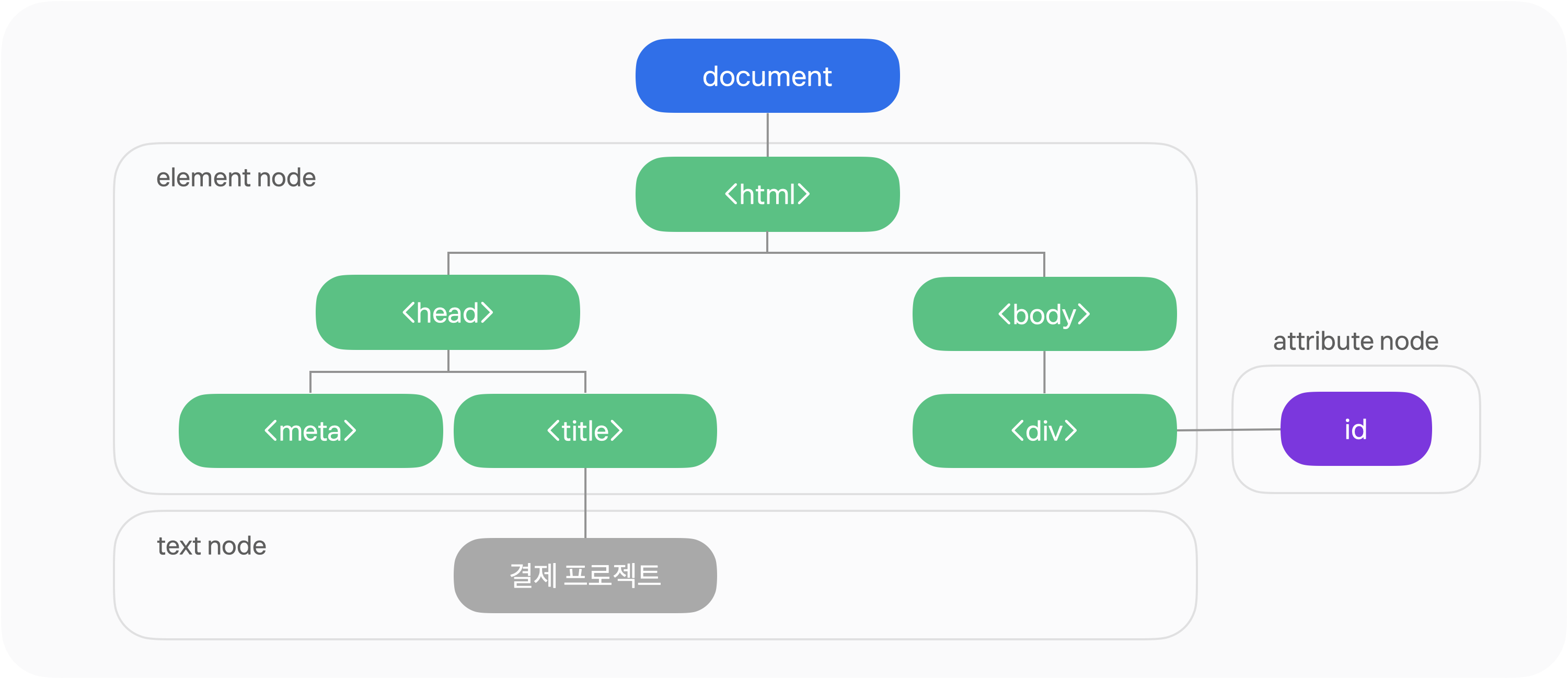
그 결과로는 위와 같은 트리 구조가 만들어지는데, document가 트리의 최상단 Node 가 된다. 이후 html tag 들이 자식 노드로서 만들어지는 구조다.
또한, 이 자식 node 들은 3가지로 나눌 수 있는데
- element node(HTML 요소)
- attribute node(id나 class 같은 것)
- text node(말 그대로 text)
DOM 이 만들어지는 순서
예전에 강의를 들을 때도, HTML 문서에서 <script> 태그를 작성할 때 제일 마지막에 작성해주는게 좋다는 말을 들었다.
그 이유는 바로 HTML parser 가 DOM 객체를 만드는 과정에 있는데, parser 가 HTML 문서를 읽어가며 DOM 을 생성해가다가 <script> 태그를 만나면 DOM 객체 생성을 멈추고 이 태그 내부에 정의된 코드를 먼저 실행하고 나서 다시 남은 HTML 문서를 읽어나가기 때문이다.
이 때문에, DOM 객체 생성이 아직 이루어지지 않은 요소에 접근하는 코드가 있을 경우 제대로 실행이 되지 않는 문제가 발생한다.
그래서, <script>를 HTML 문서 최하단에 작성하면 DOM 객체 생성이 지연되지 않기 때문에 모든 코드가 의도한대로 실행될 것이다.